
AI Output Disclosures: Use, Provenance, Adverse Incidents
Those impacted by an AI system should know when AI is being used.122 Some commenters expressed support for disclosing the use of AI when people interact with AI-powered customer service tools (e.g., chatbots).123 The Blueprint for AIBoR posited that individuals should know when an automated system is being used in a context that may affect that individual’s rights and opportunities.124 Indeed, such transparency is already required by law if failure to disclose violates consumer protections.125 In its attempt to effectuate a requirement for such notice in the employment context, New York City is now requiring that employers using AI systems in the hiring or promotion process inform job applicants and employees of such use.126 Several states require private entities to disclose certain uses of automated processing of personal information and/or to conduct risk assessments when engaging in those uses.127
In addition to knowing about AI use in decision-making contexts, people should also have the information to make sense of AI outputs. As the Blueprint for AIBoR put it, people should be “able to understand when audio or visual content is AI-generated.”128 One commenter argued that when products “simulate another person,” they “must either have that person’s explicit consent or be clearly labeled as ‘simulated’ or ‘parody.’”129 This is especially important in the context of AI-generated images or videos that depict an intimate image of a person without their consent, given the evidence that victims of image-based abuse experience psychological distress.130 Commenters expressed worry about alterations to original “ground truth” content or fabrications of real-seeming content, such as deep fakes or hallucinated chatbot outputs.131 Some commenters pointed to the particular dangers of generative AI faking scientific work and other scholarly output, and thought these merited requirements that systems disclose information about training data.132
There is a family of methods to make AI outputs more identifiable and traceable, the development of which should be a high priority and requires both technical and non-technical contributions. Recognizing this need, the AI EO tasks the Commerce Department with “develop[ing] guidance regarding the existing tools and practices for digital content authentication and synthetic content detection measures.”133 Notably, one of the objectives of the AI EO is to establish provenance markers for digital content – synthetic or not -- produced by or on behalf of the federal government.
- Provenance refers to the origin of data or AI system outputs.134 For training data, relevant provenance questions might be: Where does the material come from? Is it protected by copyright, trademark, or other intellectual property rights? Is it from an unreliable or biased dataset? For system outputs, provenance questions might be: What system generated this output? Was this information altered by AI or other digital tools?
- Authentication is a method of establishing provenance via verifiable assertions about the origins of the content. For example, C2PA is a membership organization (including Adobe and Microsoft as members) developing an open metadata standard for images and videos that allows cryptographic verification of assertions about the history of a piece of content, including about the people, devices, and/or software tools involved in its creation and editing. Content authors, publishers (e.g., news organizations), and even device manufacturers can opt-in to attach digital signatures to a piece of digital content attesting to its origins. These signatures are designed to be tamper-proof: if the attestations or the underlying content are altered without access to a cryptographic signing credential held by the content author or publisher, they will no longer match.135 Authentication-based provenance metadata could be produced for AI-generated content, either as part of the media files or in a standalone ledger. Because digital signatures do not change the underlying content, the content can still be reproduced without the signatures.136 Provenance tracking has relevance for content not generated by AI as well. If provenance data become prevalent, user perceptions and expectations may change. The absence of such data from a given piece of content could trigger suspicion that the content is AI-originated.
- Watermarking is a method for establishing provenance through “the act of embedding information, which is typically difficult to remove, into outputs created by AI—including into outputs such as photos, videos, audio clips, or text—for the purposes of verifying the authenticity of the output or the identity or characteristics of its provenance, modifications, or conveyance.”137 These techniques change the generated text, image, or video in a way that is ideally not easily removable and that may be imperceptible to humans, but that enables software to recognize the content as AI-produced and potentially to identify the AI system that produced it.138 Google DeepMind, for example, has launched (in beta) its SynthID tool for AI-generated images, which subtly modifies the pixels of an image to embed an invisible watermark that persists even after the application of image filters and lossy compression.139 Watermarking approaches are more mature for video and photos than for text, although some have proposed that text generation models could watermark their outputs by “softly promoting” the use of certain words or snippets of text over others.140 Because watermarking embeds provenance information directly into the content, the provenance data follows the content as it is reproduced. However, watermark detection tools, especially for text, may be able to provide only a statistical confidence score, not a definitive attribution, for the content’s origins.
- Content labeling refers to informing people as part of the user interface about the source of the information they are receiving. Platforms that host content, linear broadcasters or cable channels that transmit it, and generative AI systems that output information are examples of entities that could provide content labeling. Content labeling presumes that the provenance of the content can be established – e.g., via users marking AI-generated content they submit as such, via authentication metadata attached to the content files, or via watermarks indicating AI origins.
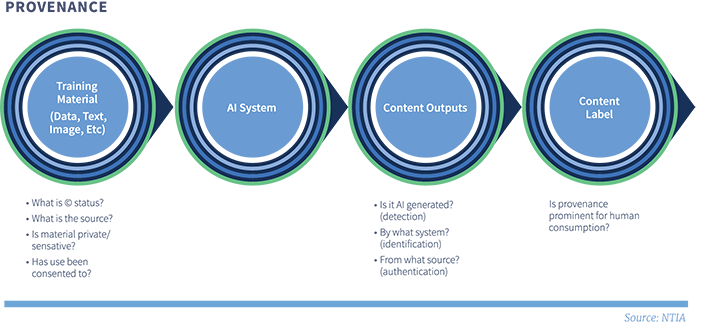
Different types of information about AI system outputs can serve complementary roles in establishing and communicating provenance. Suppose a user who sees a video when scrolling through a social media site wants to know whether the video is authentic (for example, that it was issued by a specific media organization) and whether it is known to be AI-generated content. Content labeling is one way in which the social media site can deploy tools to serve both interests – perhaps by presenting distinctive visual banners for content accompanied by origin metadata or an identifiable embedded watermark.
For a user to reap the full benefits of watermarking methods, the watermark must be resistant to removal along the way from production to distribution. That technical challenge is matched by a logistical one: the machines embedding the watermark and those decoding it must agree on implementation. A system for providing or authenticating information between machines requires shared technical protocols for those machines to follow as they produce and read the information. Therefore, applications (e.g., browsers, social media platforms) will have to recognize and implement protocols that are widely adopted.141 Similarly, for users to benefit from cryptographically signed metadata-based authentication technology, an authentication standard must be widely adopted among content producers as well as consumer-facing applications distributing content.
All these steps present challenges. First, ensuring that AI models include watermarking on AI-generated content, for example, will not be easy, especially given the difficulty of corralling open-source models used for both image and text generation. Second, there is the task of reaching consensus on the proper standard for use by consumer-facing applications. And third, preventing the removal of the watermark (i.e., an adversarial attack) between generation and presentation to the consumer will pose technical challenges. Current forms of watermarking involve keeping the “exact nature” of a watermark “secret from users,”142 or at least sharing some information between the systems generating and checking for the watermark that is unknown to those seeking to remove it. Such secrecy may be impossible, especially if open-source systems are to be able to embed watermarks and open-source applications are to be able to recognize them. Interpretive challenges abound as well: that a piece of content has been authenticated does not mean it is “true” or factually accurate, and the absence of authentication or provenance information does not necessarily support conclusions about content characteristics or origination.
One of the voluntary commitments some AI companies have made is to work on information authentication and provenance tracking technologies, including related transparency measures.143 This is important for many reasons that go beyond AI accountability, including the protection of democratic processes, reputations, dignity, and autonomy. For AI accountability, provenance and authentication help users recognize AI outputs, identify human sources, report incidents of harm, and ultimately hold AI developers, deployers, and users responsible for information integrity. Policy interventions to help coordinate networked market adoption of technical standards are nothing new. The government has done that in areas as diverse as smart chip bank cards, electronic medical records, and the V-Chip television labeling protocol. The AI EO takes a first step in promoting provenance practices by directing agency action to “foster capabilities...to establish the authenticity and provenance of digital content, both synthetic and not synthetic…”144
Two additional applications of transparency around AI use take the form of adverse incident databases and public use registries. The OECD is working on a database for reporting and sharing adverse AI incidents, which include harms “like bias and discrimination, the polarisation of opinions, privacy infringements, and security and safety issues.”145 The benefit of such a database, as one commenter put it, is to “allow government, civil society, and industry to track certain kinds of harms and risks.”146 Adequately populating the database could require either incentives or mandates to get AI system deployers to contribute to it. Beyond that, individuals and communities would need the practical capacities to easily report incidents and make actionable the reports of others. Any such database should include incidents, and not only actual harms, because “safe” means more than the absence of accidents.
There are now many jurisdictions requiring or proposing that at least public entities publicize their use of higher risk AI applications,147 as the federal government has begun doing online by publishing federal agency AI use cases at AI.gov (both high-risk and not high-risk applications).148 The Office of Management and Budget (OMB) has released draft guidance for federal agencies which would require them to publicly identify the safety-affecting and rights-affecting AI systems they use.149 As one commenter noted, a national registry for high-risk AI systems could provide nontechnical audiences with an overview of the system as deployed and the actions taken to ensure the system does not violate people’s rights or safety.150 Along with a registry of systems, a government-maintained registry of professional AI “audit reports that is publicly accessible, upon request” would foster additional accountability.151 Any such registry would have to reflect the proper balance between transparency and the potential dangers of exposing AI system vulnerabilities to malign actors.
122 See, e.g., CDT Comment at 22-23; Adobe Comment at 4-6.
123 See, e.g., Information Technology Industry Council (ITI), supra note, at 9 (“Organizations should disclose to a consumer when they are interacting with an AI system”); AI Audit Comment at 5 (recommending an “AI Identity” mark for AI chatbots and models so as to “always make it clear that the user is interacting with an AI, and not a human”).
124 Blueprint for AIBoR at 6 (“[Y]ou should know that an automated system is being used and understand how and why it contributes to outcomes that impact you.”).
125 See, e.g., See Consumer Financial Protection Bureau, Consumer Financial Protection Circular 2022-03 (May 26, 2022).
126 The New York City Council, A Local Law to Amend the Administrative Code of the City of New York, in Relation to Automated Employment Decision Tools, Local Law No. 2021/144 (Dec. 11, 2021).
127 See, generally National Conference of State Legislatures, Artificial Intelligence 2023 Legislation (September 27, 2023) (compiling state-level AI legislation including legislation imposing disclosure, opt-out, and/or risk assessment requirements).
128 Blueprint for AIBoR at 3.
129 Salesforce Comment at 5.
130 See, e.g., Nicola Henry, Clare McGlynn, Asher Flynn, Kelly Johnson, Anastasia Powell, & Adrian J. Scott, Image-Based Sexual Abuse: A Study on the Causes and Consequences of Non-Consensual Nude or Sexual Imagery, at 7-15 (2021) (reporting on a study of “image-based sexual abuse”).
131 See example., #She Persisted Comment at 3 (“Faster AI tools for election-related communication and messaging could have a profound impact on how voters, politicians, and reporters see candidates, campaigns and those administering elections”); International Center for Law & Economics Comment at 12 (“There are more realistic concerns that these very impressive technologies will be misused to further discrimination and crime, or will have such a disruptive impact on areas like employment that they will quickly generate tremendous harms.”); Center for American Progress Comment at 5 (“Evidence of this adverse effect of AI has already started to appear: automated systems have discriminated against people of color in home loan pricing, recruiting and hiring automated systems have shown a bias towards male applicants, AI used in making health care decisions have shown a racial bias that ultimately afforded white patients more care, among other examples.”).
132 See, e.g., International Association of Scientific, Technical, and Medical Publishers (STM) Comment at 4 (recommending “an accounting with respect to provenance” and an “audit mechanism to validate that AIs operating on scientific content do not substantially alter their meaning and are able to provide a balanced summary of possibly different viewpoints in the scholarly literature.”).
133 AI EO at Sec. 4.5. See also id. at Sec. 2(a) (referring to “labeling and content provenance mechanisms”).
134 NIST has defined provenance in National Institute for Standards and Technology, Risk Management Framework for Information Systems and Organizations: A System Life Cycle Approach for Security and Privacy, NIST Special Publication 800-37, Rev. 2, at 104 (December 2018) (“The chronology of the origin, development, ownership, location, and changes to a system or system component and associated data.”).
135 C2PA, C2PA Explainer.
136 See generally Sayash Kapoor and Arvind Narayanan, How to Prepare for the Deluge of Generative AI on Social Media, Knight First Amendment Institute (June 16, 2023) (criticizing the approach for being limited to those who opt-in, creating a negative space for most content which will not be authenticated).
137 AI EO at Sec. 3(gg).
138 Lauren Leffer, “Tech Companies’ New Favorite Solution for the AI Content Crisis Isn't Enough,” Scientific American (Aug. 8, 2023).
139 Sven Gowal and Pushmeet Kohli, Identifying AI-generated images with SynthID, Google DeepMind (Aug. 29, 2023).
140 John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein, A Watermark for Large Language Models, Proceedings of the 40th International Conference on Machine Learning, PMLR, Vol. 202, at 17061-17084 (2023).
141 See C2PA Comment at 4 (“Until both creator platforms and displaying mechanisms (social media, browsers, OEMs) work together to increase transparency and accountability through provenance, it will continue to be a barrier.”).
142 See Leffer, supra note 138.
143 First Round White House Voluntary Commitments at 3; Second Round White House Voluntary Commitments at 2-3.
144 AI EO at Sec. 4.5.
145 OECD.AI Policy Observatory, Expert Group on AI Incidents. A beta version of a complementary project to develop a global AI Incidents Monitor (AIM), using as a starting point AI incidents reported in international media, was released in November 2023. See The OECD AI Incidents Monitor: an evidence base for effective AI policy.
146 AI Policy and Governance Working Group Comment at 7.
147 See, e.g., Marion Oswald, Luke Chambers, Ellen P. Goodman, Pam Ugwudike, and Miri Zilka, The UK Algorithmic Transparency Standard: A Qualitative Analysis of Police Perspectives (July 7, 2022), at 6-7 (noting that “[s]everal jurisdictions have mandated levels of algorithmic transparency for government bodies” and citing several examples); Government of Canada, Directive on Automated Decision-Making (April 2023), (requiring certain Canadian government officials to indicate that a decision will be made via automated decision systems (6.2.1.), release custom source code owned by the Government of Canada (6.2.6), and document decisions of automated decision systems (6.2.8)); Central Digital and Data Office and Centre for Data Ethics and Innovation, Algorithmic Transparency Recording Standard Hub (January 5, 2023), (program through which public organizations in the United Kingdom can “provide clear information about the algorithmic tools they use, and why they’re using them.”); Connecticut Public Act No. 23-16 ("An Act Concerning Artificial Intelligence, Automated Decision-making, and Personal Data Privacy”) (June 7, 2023) (Connecticut law requiring a publicly available inventory of systems that use artificial intelligence in the government, including a description of the general capabilities of the systems and whether there was an impact assessment prior to implementation); State of Texas, An Act relating to the creation of the artificial intelligence advisory council (H.B. No. 2060, 88th Legislature Regular Session) (Texas law requiring an inventory “of all automated decision systems that are being developed, employed, or procured” by state executive and legislative agencies); California Penal Code § 1320.35 (California law requiring pretrial services agencies (local public bodies) to validate pretrial risk assessment tools and make validation studies publicly available); State of California, Assembly Bill AB-302, “An act to add Section 11546.45.5 to the Government Code, relating to automated decision systems” (California Legislature, 2023-2024 Regular Session) (Chapter 800, Statutes of 2023) (California statute requiring “a comprehensive inventory of all high-risk automated decision systems that have been proposed for use, development, or procurement by, or are being used, developed or procured by, any state agency”); State of California, Senate Bill SB-313, “An act to add Chapter 5.9 (commencing with Section 11549.80) to Part 1 of Division 3 of Title 2 of, the Government Code, relating to state government” (California Legislature, 2023-2024 Regular Session) (unenacted bill) (California bill that would require a state agency using “generative artificial intelligence” to communicate with a person to inform the person about the AI use); Commonwealth of Massachusetts, Bill H.64, “An Act establishing a commission on automated decision-making by government in the Commonwealth” (193rd General Court) (unenacted bill) (Massachusetts bill that would create a state commission to study and make recommendations on the government use of automated decision systems “that may affect human welfare” and issue a public report to “allow the public to meaningfully assess how such system functions and is used by the state, including making technical information about such system publicly available.”).
148 AI.gov, “The Government is Using AI to Better Serve the Public”.
149 OMB Draft Memo at 4.
150 See Governing AI, supra note 47, at 23.
151 AI Policy and Governance Working Group Comment at 7. See also id. (alternatively recommending that policymakers require “professional auditors to report results to regulatory authorities (similar to environmental audits), [or] require responses to recommendations made in evaluation reports within a certain time period.”).